공명 주파수 다른 7개 채널 존재하여 모든 음역대의 소리에 민감해 … 기존 음성 인식 센서에 비해 화자 인식 오류 75% 가량 감소
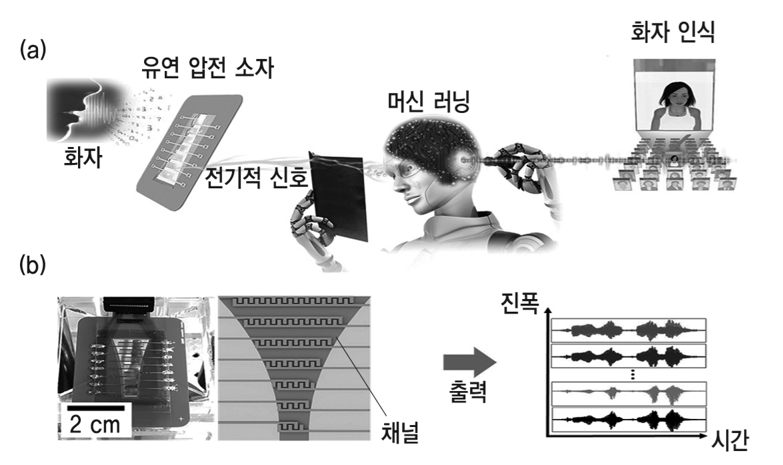
신소재공학과 이건재 교수와 전기및전자공학부 유창동 교수 공동연구팀이 달팽이관의 기저막을 모사하여 음성을 민감하게 감지할 수 있는 센서를 개발하고, 이를 활용하여 머신 러닝을 기반으로 한 화자 인식 기술의 정확도를 향상했다. 이번 연구는 <나노 에너지(Nano Energy)> 9월호에 두 편의 논문으로 나뉘어 게재되었다.
전도성 판의 진동 감지한 기존 센서
가장 널리 사용되는 기존 음성 인식 센서인 정전 용량형 마이크로폰 센서는 두 전도성 판(Conducting layer)으로 이루어진다. 소리가 공기를 통해 울려 퍼지면 판이 진동하며 축전기의 전기 용량이 변화하고, 이를 감지하여 소리를 전기 신호로 바꾸는 원리이다. 이러한 정전 용량형 마이크로폰 센서는 특정 주파수의 음성에서 판이 크게 진동하는 것을 방지하기 위해 소자의 공명 진동수가 가청 주파수 영역을 훨씬 벗어난 큰 값을 가지도록 한다. 따라서 소리에 의한 판의 진동을 큰 폭으로 키울 수 없기 때문에 센서의 감도가 낮다. 또한, 센서에 항상 전력이 공급되어야 하므로 배터리가 낭비되는 단점도 있었다.
넓이 다른 7개의 채널이 음성 감지해
이를 극복하기 위해, 연구팀은 인간 달팽이관의 기저막 구조를 모사한 유연 압전* 음성 센서를 개발하였다. 달팽이관의 기저막은 귀의 외부에 가까운 기저부(Base)에서 내부에 가까운 첨부(Apex)로 갈수록 넓이가 넓어지고, 넓이가 넓은 첨부에서 더 낮은 주파수의 소리를 감지한다. 유연 압전 음성 센서는 총 7개의 얇은 채널로 구성되어 기저막과 마찬가지로 아래로 갈수록 채널의 넓이가 넓어져 낮은 주파수의 소리를 더 잘 감지한다. 각각의 채널은 가청 주파수 영역 내에서 각자의 공명 진동수를 가져 센서의 감도도 기존에 비해 증가시킬 수 있다. 또 센서에 사용된 PZT(Pb[ZrxTi1-x]O3)는 소리에 의한 진동으로 전기적 신호를 발생시키는 압전 소재로, 외부에서 전력을 공급할 필요가 없다. 또한 유연 압전 센서는 하나의 소리 정보가 입력되어도 7개의 신호를 발생하므로, 음성 정보를 더 정확히 감지하고 전달할 수 있다.
머신 러닝 기반의 화자 인식에 적용돼
연구팀은 유연 압전 센서를 이용하여 사람 목소리를 구별하는 머신 러닝 기반 화자 인식 기술을 개발하였다. 먼저 센서가 출력한 시간에 따른 소리의 진폭 정보를 FFT(Fast Fourier Transform) 알고리즘을 적용하여 진동수에 따른 소리의 진폭 정보로 변환한다. FFT는 특정한 시점에서의 정보만을 변환하기 때문에, STFT(Short Time Fourier Transform) 알고리즘으로 전체 시간을 짧은 시간 간격으로 나누어 변환하는 과정을 거치게 된다. 이렇게 변환된 신호 정보를 GMM**(Gaussian Mixture Model) 기반의 머신 러닝 기법으로 센서에 학습시켰다. 그 결과 7개의 신호 정보 중 소리에 가장 크게 반응한 2개 채널의 신호 정보를 평균 내었을 때 97.5%의 정확도로 화자를 인식할 수 있었다. 이는 기존의 정전 용량형 마이크로폰 센서보다 오류의 빈도를 75% 가량 줄인 것이다.
연구팀은 후속 연구로 무향실이 아닌 일상생활 환경에서 센서 적용, 유연 압전 음성 센서에 적합한 머신 러닝 알고리즘 개발 등을 진행하고 있다. 이번 연구에 참여한 한재현 박사 과정, 홍성광 박사는 “노이즈가 있는 환경에서 센서의 성능을 시험해보고 있다”며, “지금은 사무실 환경에서도 작동할 수 있는 센서 개발에 집중하고 있다”고 연구의 향후 진행 방향을 설명했다.
압전*
어떤 물체에 기계적 일그러짐을 가함으로써 유전 분극이 일어나는 현상.
GMM**
여러 개의 가우시안 분포를 혼합하여 복잡한 확률 분포를 나타내는 방법.