전기및전자공학부 황의종 교수 연구팀:
Improving Fair Training under Correlation Shifts - 「ICML 2023」
우리 학교 전기및전자공학부 황의종 교수 연구팀이 학습 상황과 달라진 새로운 분포의 테스트 데이터에 대해서도 편향되지 않은 판단을 내리도록 돕는 새로운 모델 훈련 기술을 개발했다. 본 연구는 머신러닝 최고권위 국제학술 대회인 ‘국제 머신러닝 학회(ICML)’에서 발표됐다.
인공지능 공정성 문제 대두
인공지능 기술이 사회 전반에 걸쳐 광범위하게 활용되며 인간의 삶에 많은 영향을 미치고 있다. 하지만 최근 인공지능의 긍정적인 효과 이면에 머신러닝 모델이 특정 개인 혹은 집단을 차별하는 사례가 다수 발견되었고, 이에 따라 공정성(fairness)을 고려한 머신러닝 학습의 필요성에 대한 사회적인 공감 또한 커지고 있다. 예를 들어, 범죄자의 재범 예측을 위해 머신러닝 학습에 사용되는 콤파스(COMPAS) 시스템을 기반으로 학습된 모델이 인종 별로 서로 다른 재범 확률을 부여할 수 있다는 심각한 편향성이 관찰되었다. 이 밖에도 채용, 대출 시스템 등 사회의 중요 영역에서 인공지능의 다양한 편향성 문제가 밝혀지며, 공정성을 고려한 머신러닝 학습의 필요성이 커지고 있다.
최근 다양한 AI 공정성 학습 방법론이 제안되었지만, 대부분의 연구는 AI 모델을 훈련시킬 때 사용되는 데이터와 실제 테스트 상황에서 사용될 데이터가 같은 분포(distribution)를 가진다고 가정한다. 하지만 실제 상황에서는 이러한 가정이 대체로 성립하지 않으며, 특히 학습 데이터와 테스트 데이터 내의 편향(data bias) 패턴이 크게 변화할 수 있다. 이때 테스트 환경에서 데이터의 정답 레이블과 특정 그룹 정보 간의 편향 패턴이 변경되면, 사전에 공정하게 학습되었던 AI 모델의 공정성이 직접적인 영향을 받고 다시금 악화된 편향성을 가질 수 있다.
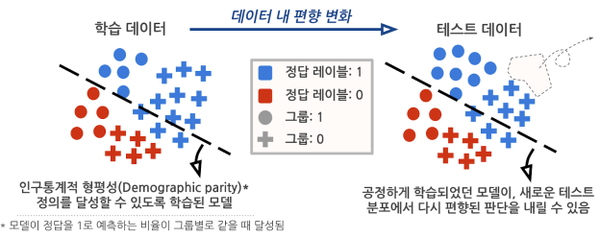
상관관계 변화 개념 도입을 통한 공정성 문제 해결
이러한 문제를 해결하기 위해, 본 연구에서는 먼저 ‘상관관계 변화(correlation shifts)' 개념을 통해 기존의 공정성을 위한 학습 알고리즘들이 가지는 정확성-공정성 트레이드오프(accuracy-fairness tradeoff)에 대한 근본적인 한계를 이론적으로 분석했다. 이때 이론적 분석의 핵심 결과는 데이터 내 편향의 정도가 모든 인공지능 모델의 달성 가능한 정확성-공정성 트레이드오프를 결정한다는 사실이다.
이러한 이론적인 분석을 바탕으로, 본 연구에서는 새로운 학습 데이터 샘플링 기법을 제안하여 테스트 시에 데이터의 편향 패턴이 변화해도 모델을 공정하게 학습할 수 있도록 하는 새로운 학습 프레임워크를 제안했다. 구체적으로는, 테스트 상황에서의 편향 정도를 예측하여 이를 반영하도록 학습 데이터의 편향 패턴을 바꾸는 데이터 샘플링을 진행한다. 본 기법을 통해 전처리된 학습 데이터는 기존의 공정성 기법에 그대로 적용할 수 있으며, 이를 통해 테스트 데이터의 분포가 변경되었을 때도 다수의 최신 공정성 학습 기법들의 성능을 더욱 높일 수 있다.
인공지능 분야에서의 무한한 응용 가능성
본 연구에서 제안된 기법은 인공지능 공정성이 요구되고 데이터가 시간에 따라 변하는 모든 분야에 적용할 수 있다. 앞으로 인공지능은 단순한 도구를 넘어서서 인간과 공존하게 될 것이라 예상되는 가운데, 신뢰 가능한 인공지능을 위해서 데이터 편향성을 극복하는 공정성을 필수적으로 고려해야 할 것이다. 특히 본 연구는 인공지능 기술의 실제 적용 환경을 고려한 연구로, 학습된 인공지능 모델들이 더욱 다양한 환경에서 신뢰할 수 있고 공정한 판단을 하도록 도울 것으로 기대된다.
제1 저자로 참여한 노유지 연구원은 몇 년간 인공지능 공정성을 위한 기법을 다양하게 개발해 오고 있다고 전했다. 특히 최근에는 이러한 기법들을 기반으로 대규모 모델 및 데이터 (large-scale models and data) 환경에서의 공정성을 높이는 연구를 진행하고 있다. 그는 ChatGPT, Bard와 같은 대규모 생성 모델들이 많은 애플리케이션에서 활용되는 과정에서 편향성을 포함한 다수의 윤리적 문제가 나타나고 있는 현재 시점에서, 연구팀의 여러 경험과 직접 개발한 기법들을 기반으로 대규모 생성 모델을 포함한 실제 인공지능 애플리케이션에서의 모델 공정성을 지속적으로 개선하고자 한다는 포부를 밝혔다.