김재철AI대학원 신기정 교수 연구팀:
NeuKron: Constant-Size Lossy Compression of Sparse Reorderable Matrices and Tensors - 「ACM WWW」
우리 학교 김재철AI대학원 신기정 교수 연구팀이 희소 행렬(Sparse Matrix)을 위한 손실 압축 알고리즘 뉴크론(NeuKron)을 개발했다. 권태형 박사과정과 고지훈 석박사통합과정이 공동 제1 저자, 전북대학교 정진홍 교수가 공동 저자로 참여한 이번 연구는 올해 5월에 미국 오스틴에서 열리는 미 컴퓨터협회 웹 학술대회에서 발표될 예정이다.
희소 행렬 압축 기술의 필요성
희소 행렬이란 행렬을 구성하는 원소 중 높은 비율이 0인 행렬을 의미한다. 전자상거래 구매 내역, 소셜 네트워크의 관계, 문서와 단어 간의 포함 관계 등 다양한 종류의 실세계 데이터가 희소 행렬의 형태로 저장 및 활용되고 있다. 추천 시스템이나 그래프 신경망 등 희소 행렬을 위한 인공지능 모델도 널리 사용되고 있다. 인공지능 모델의 학습에는 주로 병렬처리가 가능한 GPU를 활용하는데, GPU는 상대적으로 제한된 크기의 메모리를 갖는다. 이러한 메모리 제약 아래서 인공지능 모델을 학습시키기 위해서는 학습 데이터의 압축이 필요하다.
기존 대비 50배 이상의 압축률 달성
뉴크론은 희소 행렬을 위한 손실 압축 알고리즘이다. 여기서 손실 압축이란, 원본 데이터에 대한 정보를 일부 잃는 대신 높은 압축률을 달성하는 데이터 압축 방법론이다. 뉴크론을 사용할 경우, 2억 건의 비디오 시청 내역에 해당하는 희소 행렬을 10KB 크기로 압축할 수 있는데 이때, 기존 압축 기술을 활용해 1GB 크기로 압축한 것보다도 정보 손실이 적다.
손실 압축 알고리즘을 제대로 평가하기 위해서는 정보 손실의 정도와 압축 이후의 용량이라는 두 가지 측면을 동시에 고려해야 한다. 압축된 결과로 원본 데이터를 복원하였을 때의 오차를 활용해 정보 손실의 정도를 측정한다. 뉴크론은 정보 손실의 정도가 동일할 때, 압축 이후의 크기가 기존 기술 대비 50배 이상 작았다. 또한, 추천 시스템 및 그래프 신경망의 학습에 실제로 활용되는 다양한 데이터셋에 뉴크론을 적용하여 그 효용성을 검증했다.
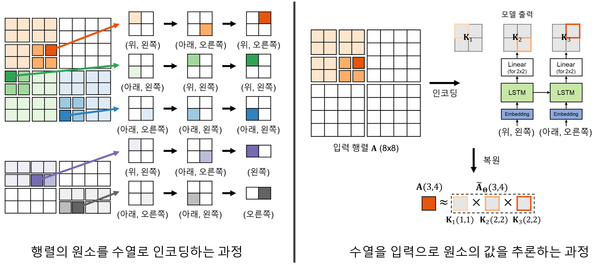
높은 압축률의 비결은 숨어 있는 자기 유사성 발견
높은 압축률을 달성하기 위해서는 데이터에 존재하는 패턴을 발견하고 이를 활용하는 것이 필수적이다. 해당 연구에서는 희소 행렬에서 흔히 발견되는 패턴인 자기 유사성(Self-Similarity)을 활용했다. 자기 유사성이란 대상의 일부분을 확대해 볼 때, 대상의 전체와 닮은 패턴이 나타나는 성질이다. 희소 행렬로 표현되는 다양한 실제 데이터에도 이런 자기 유사성이 존재하지만, 방대한 양의 데이터 속에 숨어 있기 때문에 찾아내기가 쉽지 않다.
이번 연구의 핵심은 희소 행렬의 행과 열의 순서를 재배치하여 숨어 있는 자기 유사성을 찾아내는 것이다. 주어진 행렬을 네 개의 부분 행렬로 분해하는 것을 재귀적으로 반복한다면, 각 분해 단계에서 어느 부분 행렬에 놓이는지를 기반으로 행렬의 각 원소를 수열의 형태로 표현할 수 있다. 만약 자기 유사성이 존재한다면, 비슷한 수열로 표현되는 원소끼리 유사한 값을 갖게 된다. 이렇게 원소마다 얻어진 수열을 입력으로 하여 실제 원소의 값을 추론하는 순환신경망을 학습시켰다. 순환신경망은 행렬의 자기 유사성을 기반으로 정확한 추론을 수행하고 압축된 행렬을 매우 낮은 오차로 복원할 수 있었다.
신 교수는 후속 연구에 대해 “응용 측면에서는 뉴크론을 활용하여 인공지능 모델을 경량화하는 연구를 수행하고 있다. 많은 인공지능 모델의 매개 변수도 희소 행렬의 형태이기 때문에, 뉴크론을 활용하면 이를 효과적으로 압축할 수 있을 것으로 기대 중이다.”고 설명했다. 또한, “알고리즘 측면에서는 압축에 긴 시간이 필요하다는 단점을 보완하기 위해 뉴크론의 속도를 개선하는 연구를 수행하고 있다.”고 밝혔다.
문제의 본질을 정확하게 이해하는 것이 실마리
연구 과정에서 있었던 난관에 관해 묻자, 신 교수는 “행렬의 행과 열을 재배치하는 것은 수학적으로는 최적의 순열 함수를 찾는 과정에 해당한다. 순열 함수를 위한 범용적이면서 효과적인 최적화 도구가 없기 때문에 새로운 최적화 방법을 설계하는 과정에서 많은 시행착오를 겪었다.”고 밝혔다. 해결한 과정에 대해서는 “최신 논문의 결과들을 고려하기도 했지만, 우리의 문제에는 효과적이지 않았다. 오히려 고전적인 최적화 방법을 기반으로 우리 학생들이 직접 설계한 최적화 방법이 가장 효과적이었다.”고 설명했다. 또한, “우리가 해결하고자 하는 문제의 본질을 정확하게 이해하기 위한 노력이 결실을 보았다고 생각한다.”고 전했다.