산업및시스템공학과 박찬영 교수 연구팀 : Relational Self-Supervised Learning on Graphs - 「CIKM 2022」
우리 학교 산업및시스템공학과 박찬영 교수 연구팀이 레이블링(Labeling) 과정 없이 그래프 신경망을 훈련하는 학습 모델 기술을 개발했다고 지난달 5일 밝혔다. 연구팀의 기술은 표상 공간에서 정점 간 유사도가 작아지도록 하는 기존 방식의 단점을 개선하여, 정점들 간 관계를 보존함으로써 레이블이 없는 상황에서도 모델의 학습이 가능하도록 하였다. ‘관계 보존’이라는 패러다임을 도입한 이 같은 학습 방법론은 심층 학습의 전반적인 성능 개선에도 기여할 것으로 기대된다.
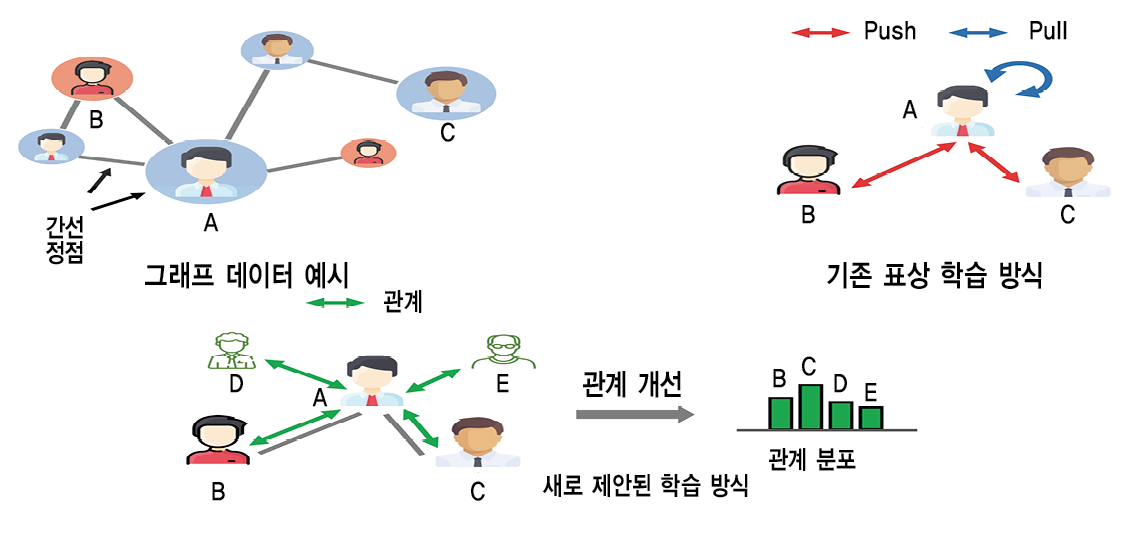
기존 학습 모델의 단점
기존의 표상 학습 방식은 각 정점의 유사도가 작아지도록 하는 훈련 방식을 차용한다. 표상 공간에서 정점들이 가능한 한 멀어지도록 학습한 후에도 여전히 가까운 거리에 위치한다면, 이들이 같은 레이블을 갖는다고 가정하는 것이다. 예를 들어, SNS(Social Network Service)에 학습 모델을 적용한 후에 가까운 거리에 위치한 사용자 A, B는 ‘20대’, ‘KAIST 학생’ 등 동일한 레이블을 적용할 수 있다.
다만 일반적으로 수작업에 의해 진행되는 레이블링의 특성 상 기존 방식은 상당한 노동력과 시간이 소요되고, 실제로는 동일한 특성을 가지고 있는 데이터들 또한 멀어지도록 학습하여 그래프 신경망(Graph Neural Network) 모델에 잘못된 신호를 전달할 수 있다. 특히 SNS의 네트워크 구조는 단순 이미지나 텍스트와 달라 일반 대중으로부터 정보를 얻는 크라우드소싱(Crowd sourcing) 방식을 통해 레이블링하기 매우 어렵다. 이는 SNS 타겟 광고에서 사용자가 좋아할 상품의 카테고리를 분류하기 어려운 것과 마찬가지이다. 따라서 레이블링 과정 없이도 정점 간 관계를 규명할 수 있는 메커니즘의 필요성이 대두되었다.
정점 간 관계를 보존하는 ‘관계 보존 학습' 방법론
연구팀은 기존 메커니즘의 단점을 보완하고자 정점 간 관계를 정의하고 이를 보존함으로써 그래프 신경망을 구현하는 방법론을 제안하였다. ‘관계 보존 학습’으로 명명된 이 방식은, 표상 공간에서 정점들이 의도한 바와 다른 방향으로 멀어지는 선택 편향 문제를 해결하기 위해 정점들의 관계를 기반으로 그래프 데이터를 학습하는 데 초점을 맞췄다.
정점 간의 관계를 계산하여 분포를 정량화하는 과정은 표상 공간에서의 코사인 유사도에 기반한다. 구글 사의 페이지랭크가 정점들 상호 간의 연결 그래프에 마르코프 체인(Markov Chain)이라는 수학적 도구를 적용하여 웹페이지들을 분석하는 방식인 반면, 관계 보존 학습은 관계 그래프의 구조에 주안점을 두기보다 우선 정점들을 표상 공간으로 이동시킨 후 그 관계를 분석하는 방법이라 볼 수 있다.
연구팀은 데이터 증강을 통해 하나의 그래프에 대한 두 가지 시각을 생성한 후 이들을 각각 온라인 네트워크, 타겟 네트워크라는 그래프 인공신경망의 입력으로 활용함으로써 다시 서로 다른 표상 공간에 나타나게 하였다. 이후엔 기존의 모델이 두 개의 시각을 표상 공간에서 정확히 일치시키도록 학습했던 것과 달리, 코사인 유사도를 통해 도출한 표상 공간 상 관계 구조가 일치하도록 모델링하였다. 특히 이러한 관계를 규정함에 있어 정점 간의 전역적(Global) 관계를 구하기 위해 샘플링을 진행한 한편, 지역적(Local) 관계를 도출하기 위해서는 페이지랭크에 적용되는 Diffusion Score를 사용하였다. 종국적으로는 상기의 전역적 및 지역적 관계를 종합하면 정점 간 주요 관계를 학습할 수 있게 된다.
관계 보존 학습 모델의 성과와 방향
연구팀은 관계 보존 학습 모델을 그래프 데이터 분석의 주요 문제인 정점 분류, 간선 예측에 적용했다. 그 결과 최신 연구 방법론과 비교했을 때, 정점 분류 문제에서 최대 3%의 예측 정확도 향상이 있었고, 간선 예측 문제에서는 6%의 성능 향상, 다중 연결 네트워크(Multiplex network)의 정점 분류 문제에서는 3%의 성능 향상을 나타났다. 이 기술이 다양한 그래프 구조로 이루어진 데이터들에 범용적으로 활용될 수 있음을 고려한다면, 이러한 성과는 SNS에서의 친구 추천이나 쇼핑 플랫폼 상의 상품 추천 등에 널리 활용될 수 있을 것이라 기대된다. 특히 레이블이 부재한 상황을 가정한 모델의 특성 상 그래프 기반의 데이터 뿐만 아니라 이미지 텍스트 음성 데이터 등에 폭넓게 적용될 수 있어, 심층 학습의 전반적인 성능 개선에 기여할 수 있을 것으로 보인다.