바이오및뇌공학과 이상완 교수 연구팀 : (논문명) Prefrontal Solution to the Bias-Variance Tradeoff During Reinforcement Learning
우리 학교 바이오및뇌공학과 이상완 교수(신경과학 인공지능 융합연구센터장) 연구팀이 뇌 기반 인공지능 기술을 이용해 인공지능의 난제 중 하나인 과적합-과소적합 상충 문제를 해결하는 원리를 풀어내는 데 성공했다.
이 교수와 전 뇌인지공학프로그램 소속 김동재 박사가 주도하고 우리 학교 바이오및뇌공학과 정재승 교수가 참여한 이번 연구는 `강화학습 중 편향-분산 상충 문제에 대한 전두엽의 해법’이라는 제목으로 국제 학술지 <셀(Cell)>의 오픈 액세스 저널인 <셀 리포트(Cell Reports)> 온라인판에 지난달 28일 게재됐다.
강화학습의 난제(과소적합과 과적합)
기계학습에는 과소적합-과적합의 위험성(underfitting-overfitting risk)이라는 오래된 난제가 있다. 주어진 문제에 맞춰 데이터를 과하게 학습한 모델의 경우 특정 문제에서는 높은 성능을 보이나, 상황이 조금만 달라지면 성능이 크게 떨어지는 경우가 많다. 이를 과적합(overfitting)의 문제라고 한다. 반대로, 데이터 다양성을 줄이거나, 과도하게 복잡한 구조로 학습할 경우, 유사한 환경에서는 안정적 성능을 얻는다. 그러나 데이터의 주어진 문제에 대해서는 최대한의 성능을 끌어낼 수 없다. 이를 과소적합(underfitting)의 문제라고 한다.
과소적합-과적합 문제에 대한 연구팀의 해법
위 연구는 해당 난제를 인간의 뇌가 이 문제를 어떻게 푸는지 기계학습 관점에서 봄으로써 해결전략을 찾았다.
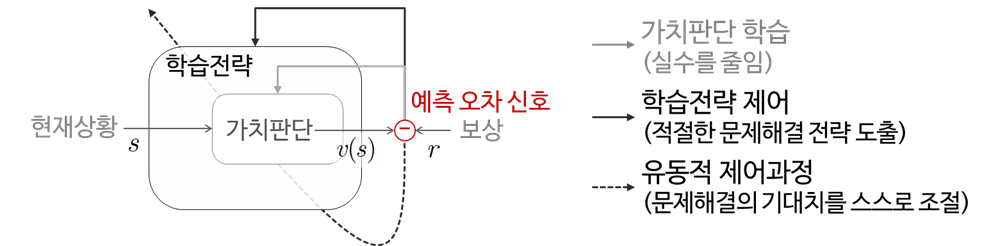
인간은 현재 주어진 문제에 집중하면서도(과소적합 문제 해결), 당면 문제에 과하게 집착하지 않고(과적합 문제 해결) 변하는 상황에 맞게 유동적으로 대처한다.
인간의 뇌는 중뇌 도파민 회로와 전두엽에서 처리되는 `예측 오차’의 하한선(prediction error lower bound)이라는 단 한 가지 정보를 이용해 ‘과소적합-과적합 문제’를 해결한다. 전두엽, 특히 복외측전전두피질은 현재 사용하고 있는 문제 해결 방식으로 주어진 문제를 얼마나 잘 풀 수 있을지에 대한 기대치의 한계를 추정한다. 예를 들어 ‘이렇게 풀면 90점까지는 받을 수 있어’라고 생각하는 것이다. 또한, 변화하는 상황에 맞춰 최적인 문제 해결전략을 유동적으로 선택하는 과정을 통해 과소적합-과적합의 위험을 최소화하기도 한다. ‘이런 방식으로는 기껏해야 70점이니 다르게 풀어보자’라고 판단한다.
연구팀은 이러한 인간의 뇌 문제 해결 방법에 주목했다. 이후 뇌 데이터, 확률과정 추론 모형, 강화학습 알고리즘을 이용해 이론적 틀을 마련한 다음, 이로부터 유동적인 메타 강화학습 모델을 도출하여 문제를 해결했다.
이 교수는 응용 가능성에 대한 질문에 “연구를 통해 개발된 메타 강화학습 모델을 이용하면 간단한 게임을 통해 인간의 유동적 문제 해결 능력을 간접적으로 측정할 수 있다”며 “스마트 교육이나 중독과 관련된 인지 행동치료에 적용할 경우 상황 변화에 유동적으로 대처하는 인간의 문제 해결 능력 자체를 향상할 수 있을 것으로 기대한다”고 밝혔다.
끝으로 이 교수는 연구를 지속하는 학생들에게 “앞뒤가 잘 맞으면 아직 제대로 이해하지 못한 것”임을 강조했다. 퍼즐 조각처럼 잘 들어맞는다는 것은 어떤 생각의 틀 안에 갇혀 있다는 반증이며 앞뒤가 잘 맞는 순간이 바로 생각 상자의 밖으로 나와야 할 때임을 역설적으로 설명하며 연구자의 덕목을 덧붙였다.